Welcome to Day 13 of 21 Days of AWS using Terraform. The topic for today is Introduction to Nat Gateway using Terraform
What is NAT Gateway
NAT gateway enables instance in Private Subnet to connect to the internet or other AWS services but prevent the internet from initiating a connection with those instances.
How NAT works
NAT device has an Elastic IP address and is connected to the Internet through an internet gateway.
When we connect an instance in a private subnet through the NAT device, which routes traffic from the instance to the internet gateway and routes any response to the instance
NAT maps multiple private IPv4 addresses to a single public IPv4 address.
NAT gateway doesn’t support IPv6 traffic for that you need to use Egress only gateway.
NOTE: IPv6 traffic is separate from IPv4 traffic, route table must include separate routes for IPv6 traffic.
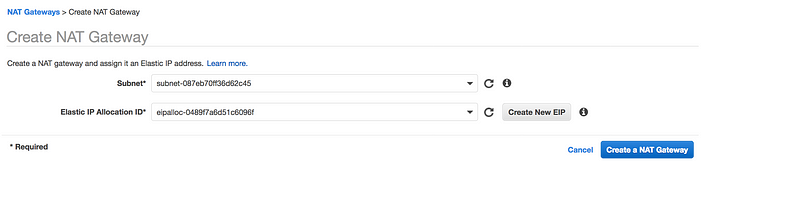
Go to VPC Dashboard → NAT Gateways → Create NAT gateways
Make sure you select the Public Subnet in your custom VPC
For NAT gateway to work, it needs Elastic IP
NOTE: NAT Gateway creation will take 10–15 min
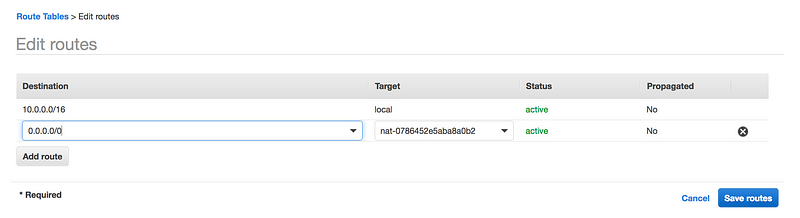
Once the NAT gateway is available, add it to your default Route table
The advantage of NAT Gateway
NAT gateway is highly available but we need it per availability zone.
Can scale up to 45Gbps
Managed by AWS
Limitation of NAT Gateway
You can associate exactly one Elastic IP address with a NAT gateway. You cannot disassociate an Elastic IP address from a NAT gateway after it’s created. To use a different Elastic IP address for your NAT gateway, you must create a new NAT gateway with the required address, update your route tables, and then delete the existing NAT gateway if it’s no longer required.
You cannot associate a security group with a NAT gateway. You can use security groups for your instances in the private subnets to control the traffic to and from those instances.
You can use a network ACL to control the traffic to and from the subnet in which the NAT gateway is located. The network ACL applies to the NAT gateway’s traffic
On Day 2 we wrote the AWS VPC code, now its time to modify that code
Welcome to Day 12 of 21 Days of AWS using Terraform. Topic for today is Introduction to CloudTrail using Terraform
What Is AWS CloudTrail?
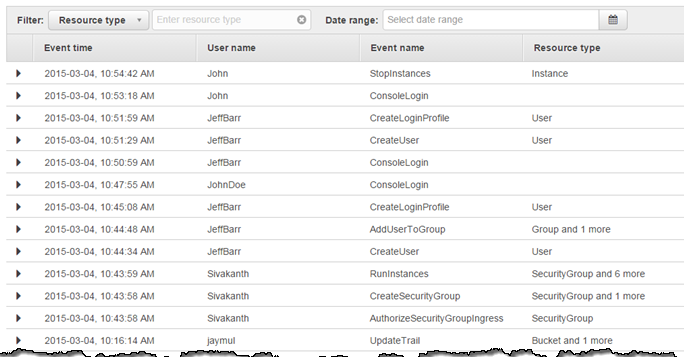
AWS CloudTrail is an AWS service that helps you enable governance, compliance, and operational and risk auditing of your AWS account. Actions taken by a user, role, or an AWS service are recorded as events in CloudTrail. Events include actions taken in the AWS Management Console, AWS Command Line Interface, and AWS SDKs and APIs.
It’s enabled when the account is created(for 7 days)
When activity occurs in your AWS account, that activity is recorded in a CloudTrail event.
Entries can be viewed in Event History(for 90 days)
Event logs can be aggregated across accounts and regions.
NOTE
Historically CloudTrail was not enabled by default
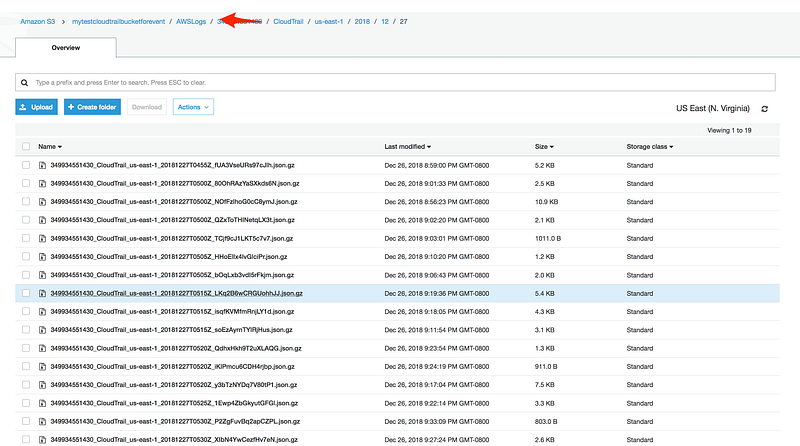
For an ongoing record of activity and events in your AWS account, create a trail. It allows us to send logs to S3 bucket and can be single or multi-region.
To create a trail
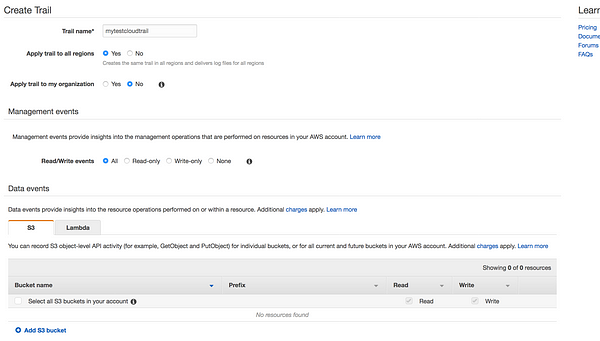
Go to AWS Console --> Management & Governance --> CloudTrail --> Trails --> Create trail
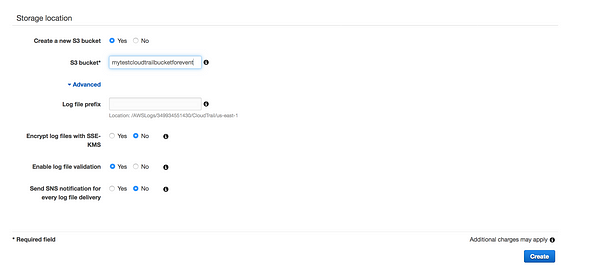
* Trail name: Give your trail name * Apply trail to all regions: You have an option to choose all regions or specific region. * Read/Write events: You have the option to filter the events * Data events: Data events provide insights into the resource operations performed on or within a resource S3: You can record S3 object-level API activity (for example, GetObject and PutObject) for individual buckets, or for all current and future buckets in your AWS account Lambda:You can record Invoke API operations for individual functions, or for all current and future functions in your AWS account. * Storage Locations: Where to store the logs, we can create new bucket or use existing bucket * Log file prefix: We have the option to provide prefix, this will make it easier to browse log file * Encrypt log file with SSE-KMS:Default SSE-S3 Server side encryption(AES-256) or we can use KMS * Enable log file validation: To determine whether a log file was modified, deleted, or unchanged after CloudTrail delivered it, you can use CloudTrail log file integrity validation * Send SNS notification for every log file delivery:SNS notification of log file delivery allow us to take action immediately
NOTE:
There is always a delay between when the event occurs vs displayed on CloudTrail dashboard. On top of that, there is an additional delay when that log will be transferred to S3 bucket.
Delivered every 5(active) minutes with up to 15-minute delay
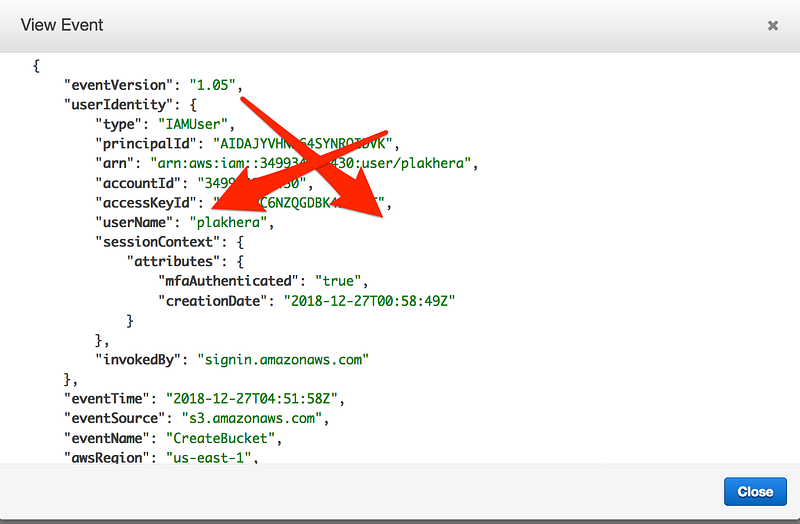
All CloudEvents are JSON structure you will see something like this when you try to view any event
Welcome to Day 11 of 21 Days of AWS using Terraform, topic for today is Introduction to S3 using terraform.
What is AWS S3?
AWS Simple Storage Service(S3) provides secure, durable and highly scalable object storage. S3 is easy to use and we can store and retrieve any amount of data from anywhere on the web.
bucket: name of the bucket, if we ommit that terraform will assign random bucket name acl: Default to Private(other options public-read and public-read-write) versioning: Versioning automatically keeps up with different versions of the same object.
NOTE: Every S3 bucket must be unique and that why random id is useful to prevent our bucket to collide with others.
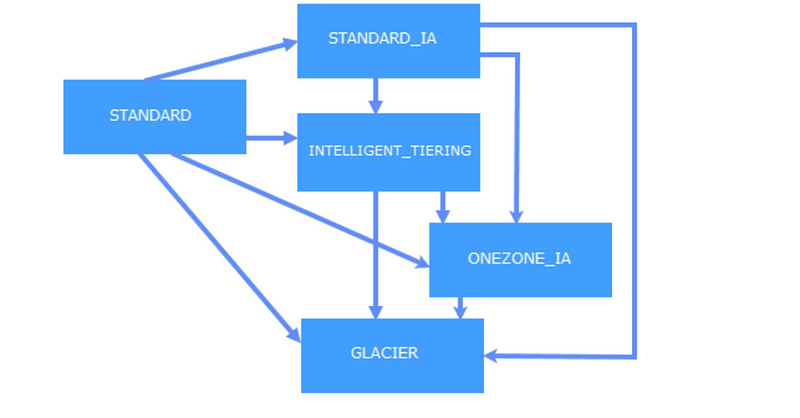
In most of the cases, data which is generated by our application is relevant for us for the first 30 days and after that, we don’t access that data as frequently.
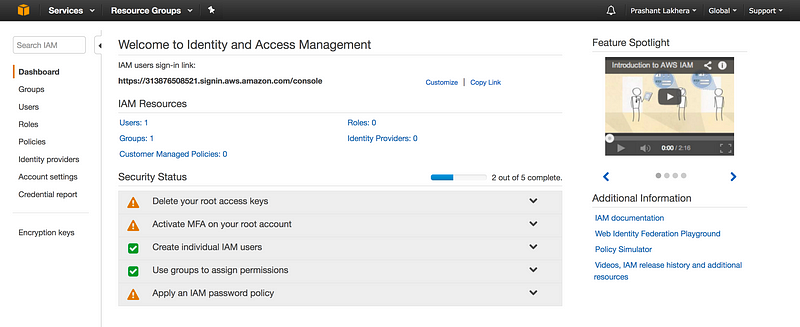
Welcome to Day 10 of 21 Days of AWS using Terraform, topic for today is Introduction to IAM using terraform.
What is IAM?
Identity and Access Management(IAM) is used to manage AWS
Users
Groups
Roles
Api Keys
IAM Access Policies
and it provide access/access-permissions to AWS resources(such as EC2,S3..)
If we notice at the right hand side at the top of console it says Global i.e creating a user/groups/roles will apply to all regions
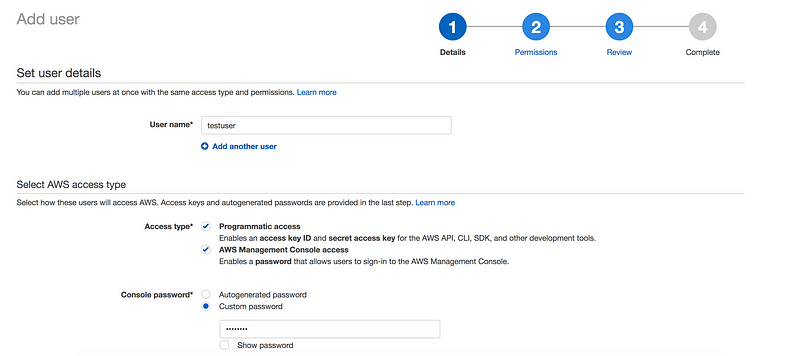
To create a new user,Just click on Users on the left navbar
By default any new IAM account created with NO access to any AWS services(non-explicit deny)
Always follow the best practice and for daily work try to use a account with least privilege(i.e non root user)
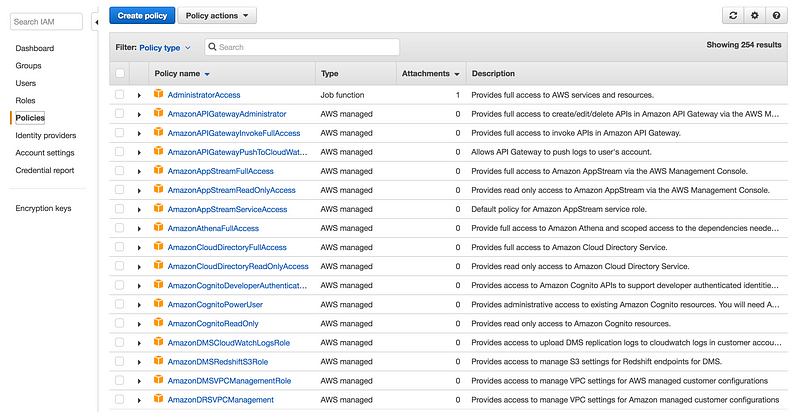
IAM Policies: A policy is a document that formally states one or more permissions.For eg: IAM provides some pre-built policy templates to assign to users and groups
Administrator access: Full access to AWS resources
Power user access: Admin access except it doesn’t allow user/group management
Read only access: As name suggest user can only view AWS resources
Default policy is explicitly deny which will override any explicitly allow policy
One way to achieve the same is copy paste the same piece of code but that defeats the whole purpose of DRY.
Terraform provides meta parameters called count to achieve the same i.e to do certain types of loops.The count is a meta parameter which defines how many copies of the resource to create.
element(list, index) — Returns a single element from a list at the given index. If the index is greater than the number of elements, this function will wrap using a standard mod algorithm. This function only works on flat lists.
OR
The element function returns the item located at INDEX in the given LIST
length(list) — Returns the number of members in a given list or map, or the number of characters in a given string.
OR
The length function returns the number of items in LIST (it also works with strings and maps)
Now when you run the plan command, you’ll see that Terraform wants to create three IAM users, each with a unique name
One thing to note as we have used count on a resource, it becomes the list of resources rather than just a single resource.
For example, if you wanted to provide the Amazon Resource Name (ARN) of one of the IAM users as an output variable, you would need to do the following:
# outputs.tf output “user_arn” { value = “${aws_iam_user.example.0.arn}” }
If you want the ARNs of all the IAM users, you need to use the splat character, “*”, instead of the index:
# outputs.tf output “user_arn” { value = “${aws_iam_user.example.*.arn}” }
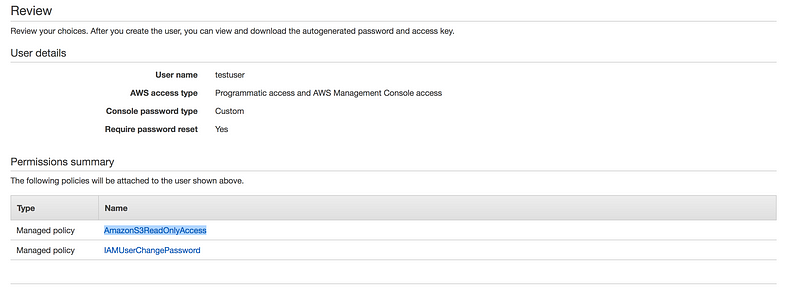
As we are done with creating IAM user, now let attach some policy with these users(As by default new user have no permission whatsoever)
IAM Policies are JSON documents used to describe permissions within AWS. This is used to grant access to your AWS users to particular AWS resources.
IAM Policy is a json document
Terraform provides a handy data source called the aws_iam_policy_document that gives you a more concise way to define the IAM policy
This code uses the count parameter to “loop” over each of your IAM users and the element interpolation function to select each user’s ARN from the list returned by aws_iam_user.example.*.arn.
Welcome to Day 9 of 21 Days of AWS using Terraform, topic for today is Introduction to Route53 using terraform.
What is AWS Route53?
Amazon Route 53 is a highly available and scalable Domain Name System (DNS) web service. You can use Route 53 to perform three main functions in any combination:
Domain Registration
DNS Routing
Health Checking
Key DNS Terms
A Record
A record is used to translate human-friendly domain names such as “www.example.com” into IP-addresses such as 192.168.0.1 (machine friendly numbers).
CNAME Record
A Canonical Name record (abbreviated as CNAME record) is a type of resource record in the Domain Name System (DNS) which maps one domain name (an alias) to another (the Canonical Name.)
NameServer Record
NS-records identify the DNS servers responsible (authoritative) for a zone.
Amazon Route 53 automatically creates a name server (NS) record that has the same name as your hosted zone. It lists the four name servers that are the authoritative name servers for your hosted zone. Do not add, change, or delete name servers in this record.
A Start of Authority record (abbreviated as SOA record) is a type of resource record in the Domain Name System (DNS) containing administrative information about the zone, especially regarding zone transfers
AWS Specific DNS Terms
Alias Record
Amazon Route 53 alias records provide a Route 53–specific extension to DNS functionality. Alias records let you route traffic to selected AWS resources, such as CloudFront distributions and Amazon S3 buckets. They also let you route traffic from one record in a hosted zone to another record.
Unlike a CNAME record, you can create an alias record at the top node of a DNS namespace, also known as the zone apex. For example, if you register the DNS name example.com, the zone apex is example.com. You can’t create a CNAME record for example.com, but you can create an alias record for example.com that routes traffic to www.example.com.
AWS Route53 Health Check
Amazon Route 53 health checks monitor the health and performance of your web applications, web servers, and other resources. Each health check that you create can monitor one of the following:
The health of a specified resource, such as a web server
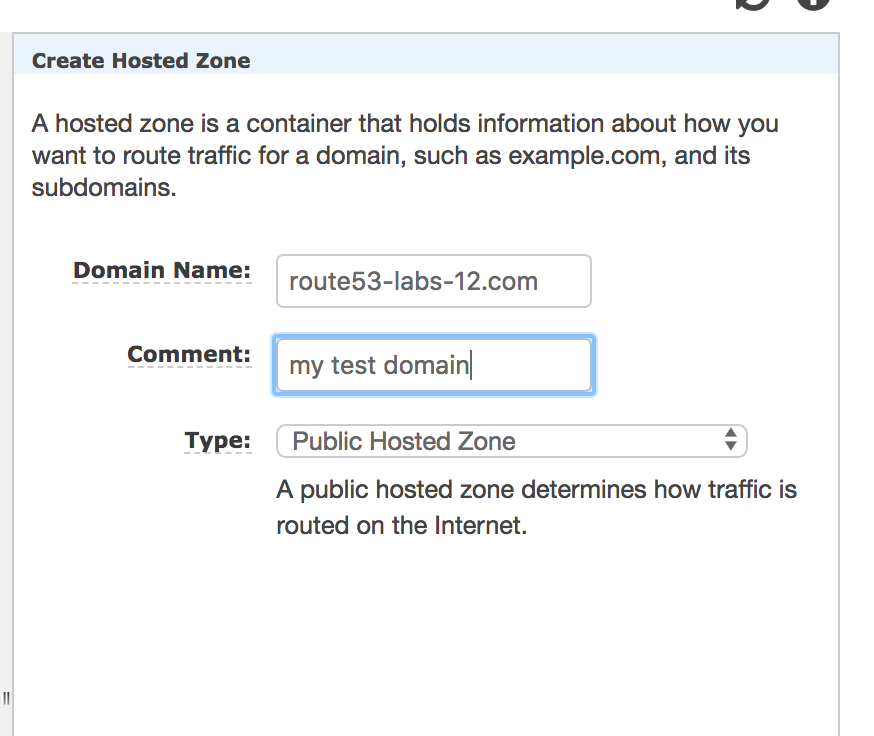
* Domain Name: You must need to purchase this domain either from your Domain Registrar or you can purchase from Amazon * Comment: Add some comment * Type: Public Hosted Zone(if purchased by a domain registrar) OR you can set Private Hosted Zone for Amazon VPC
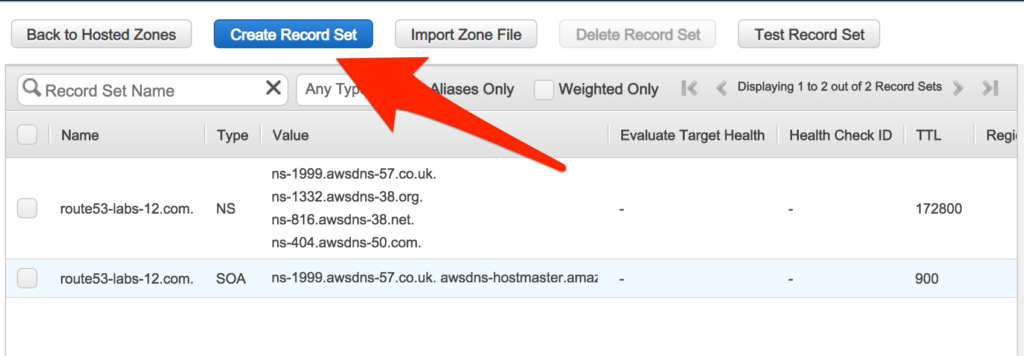
The moment you create a hosted zone four NS and SOA record will be created for you.
NOTE: Please don’t change or alter these records.
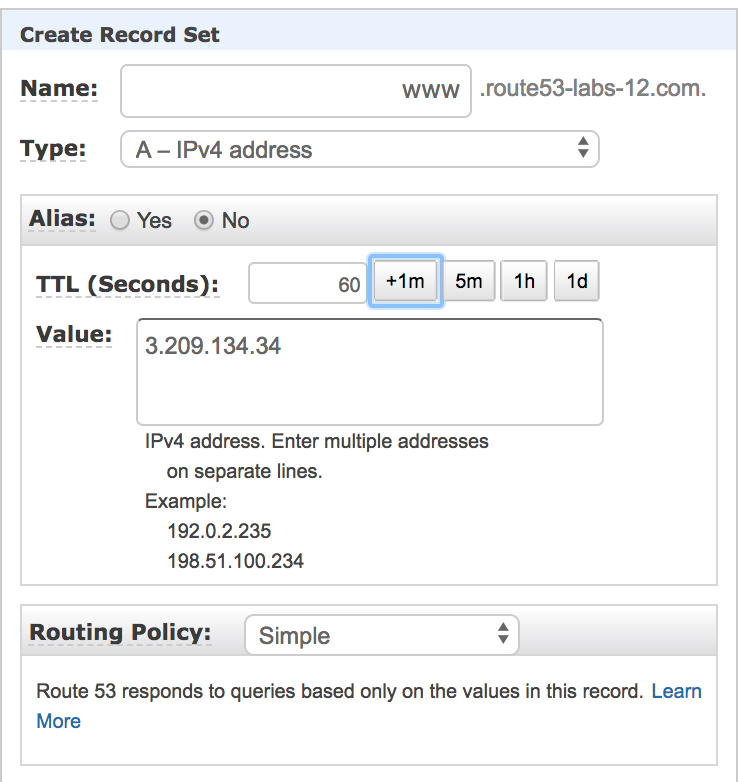
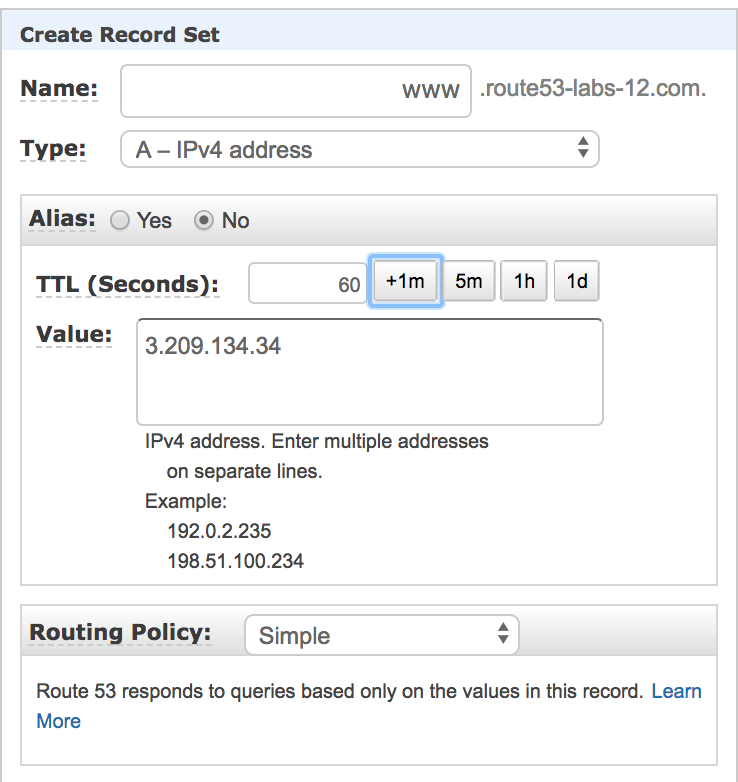
Step2: Create A record
* Name : www * Type: A-IPv4 address * Alias: No * TTL: Select +1m(60second) * Value: Public IP of your EC2 instance * Routing Policy: Simple
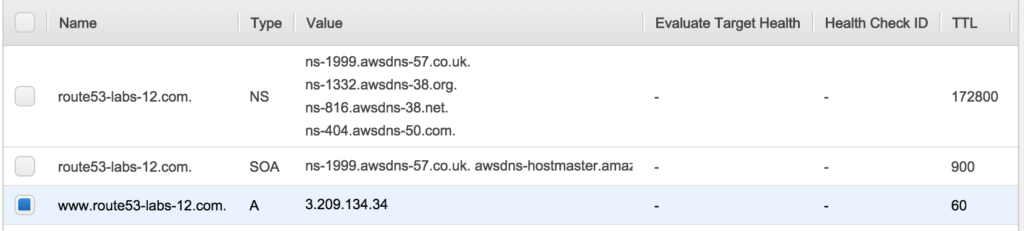
You will see the record like this
Choosing a Routing Policy
When you create a record, you choose a routing policy, which determines how Amazon Route 53 responds to queries:
Simple Routing
Simple Routing Policy use for a single resource that performs a given function for your domain, for example, a web server that serves content for the example.com website.
If you choose the simple routing policy in the Route 53 console, you can’t create multiple records that have the same name and type, but you can specify multiple values in the same record, such as multiple IP addresses. If you specify multiple values in a record, Route 53 returns all values to the recursive resolver in random order, and the resolver returns the values to the client (such as a web browser) that submitted the DNS query. The client then chooses a value and resubmits the query.
As you can see in the above case we are using Simple Routing Policy.
Let’s automate this with the help of terraform code
records – (Required for non-alias records) A string list of records
Here I am using element function
element retrieves a single element from a list.
element(list, index)
The index is zero-based. This function produces an error if used with an empty list.
Use the built-in index syntax list[index] in most cases. Use this function only for the special additional "wrap-around" behavior described below.
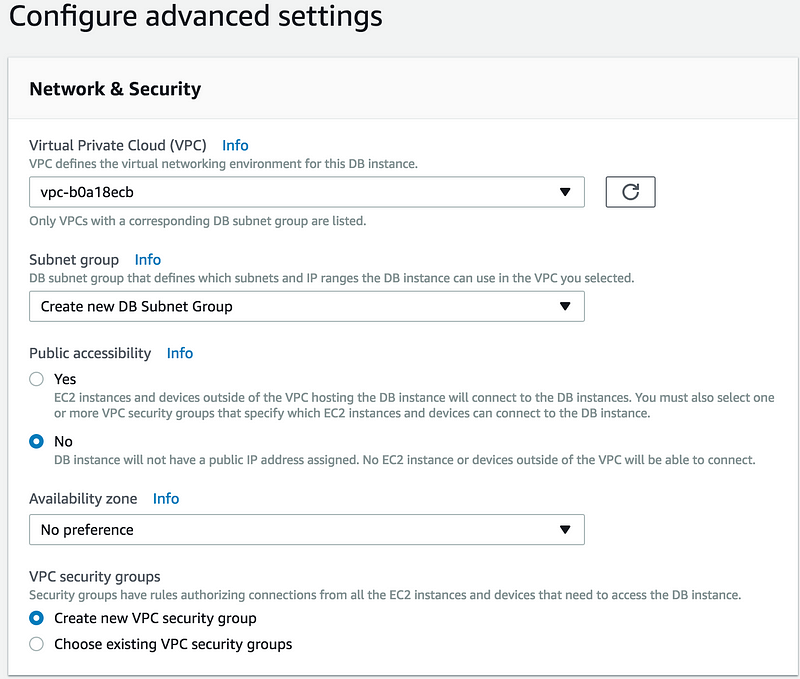
Welcome to Day 8 of 21 Days of AWS using Terraform. The topic for today is Introduction to AWS RDS MySQL using Terraform. With that we will be able to finish the last part of our two-tier architecture i.e MySQL DB is private subnets.
What is AWS RDS?
Amazon Relational Database Service (Amazon RDS) is a web service that makes it easier to set up, operate, and scale a relational database in the cloud. It provides cost-efficient, resizable capacity for an industry-standard relational database and manages common database administration tasks.
To create a database, go to Database section(AWS Console) and click on RDS
Click on Get Started Now
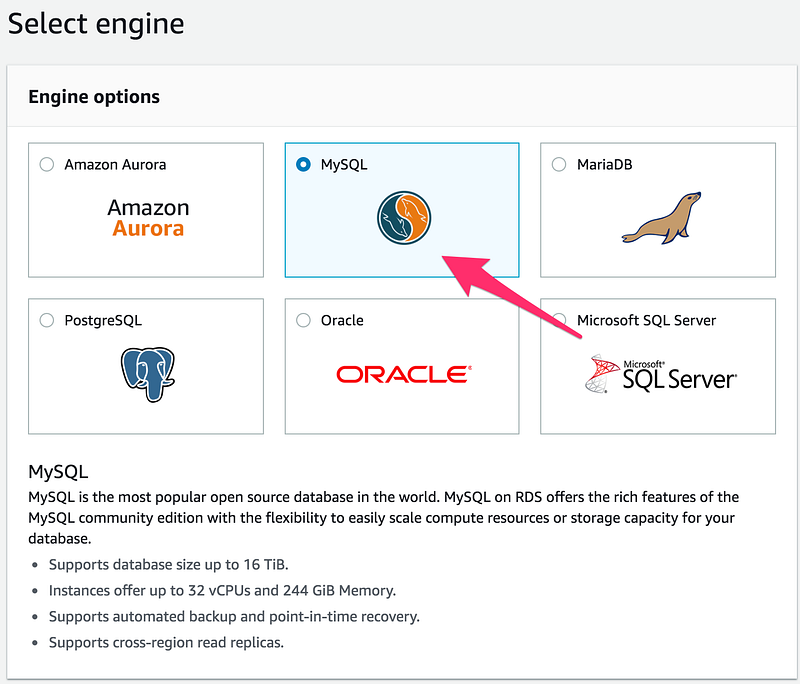
Then Select MySQL
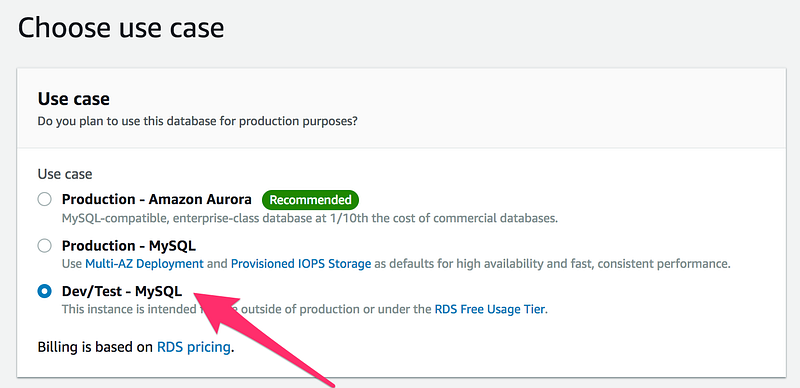
On the next screen, choose Dev/Test -MySQL(or depend upon your requirement, as my use case is only for testing purpose)
On the next screen provide all the info
As this is for testing Purpose
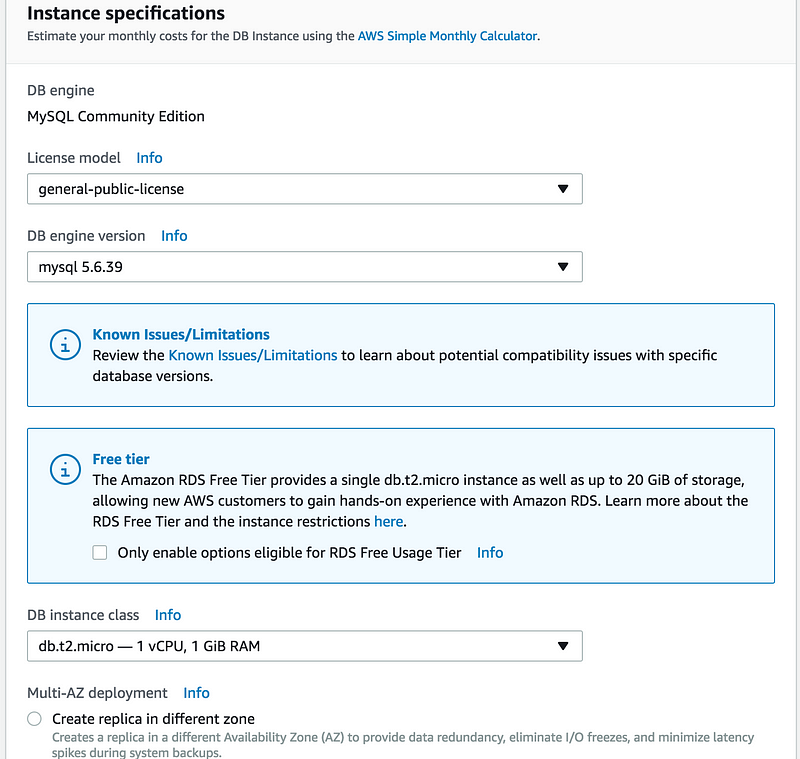
DB instance class(db.t2.micro)
Skip MultiAZ deployment for the time being
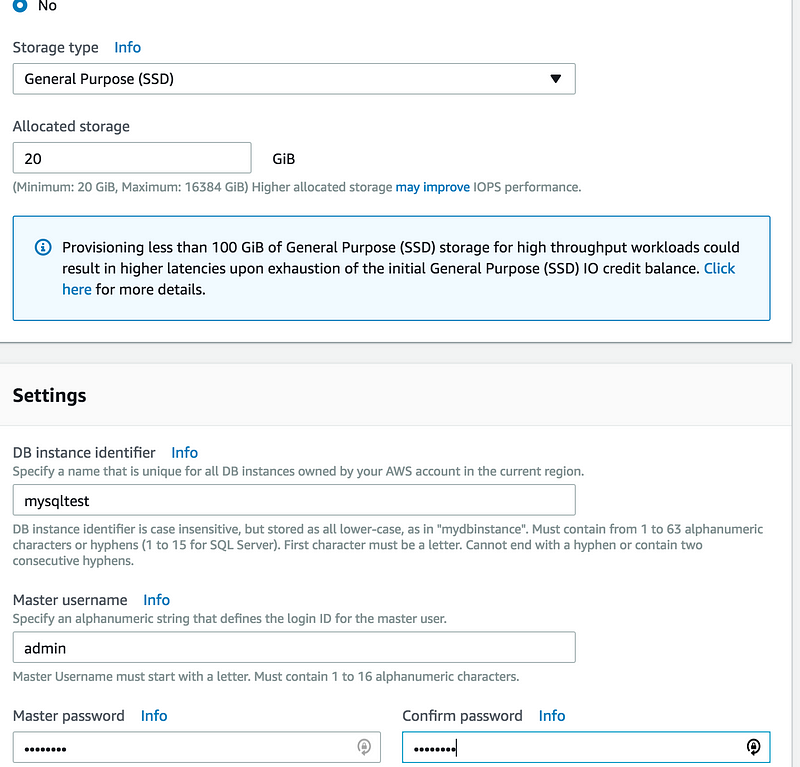
Gave all the info like(DB instance identifier, Master username, Master password)
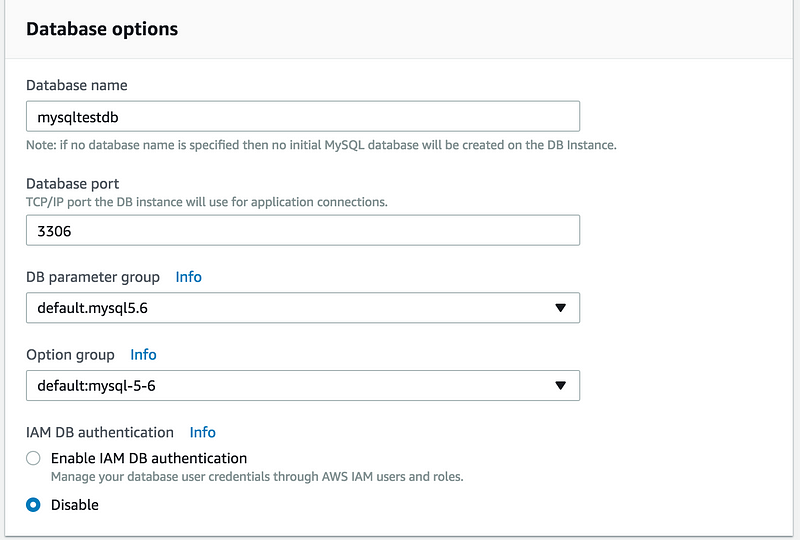
Fill all the details in the next screen
Mainly you need to fill
Database name(Don’t confuse it DB instance identifier)
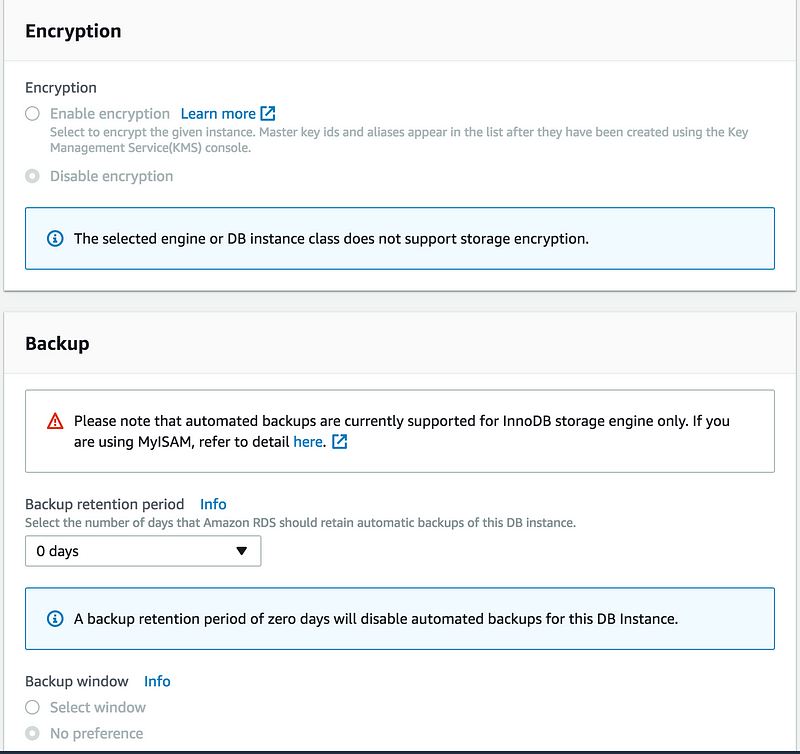
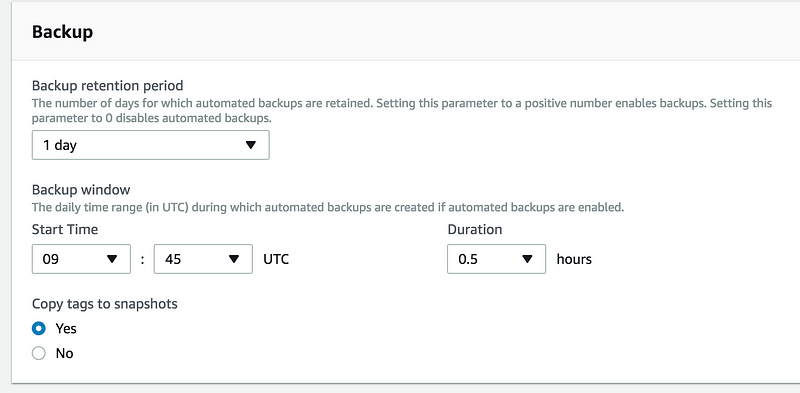
Backup retention period(0 days, for the time being)
Then click on Launch DB instance
Wait for few mins 5–10min(or depend upon your instance type and size) and check Instance Status(It should be available)
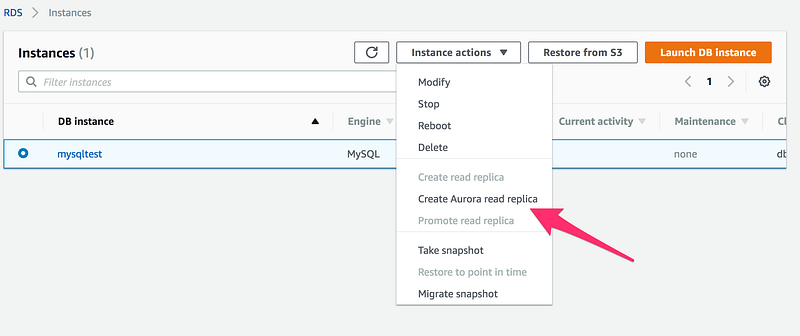
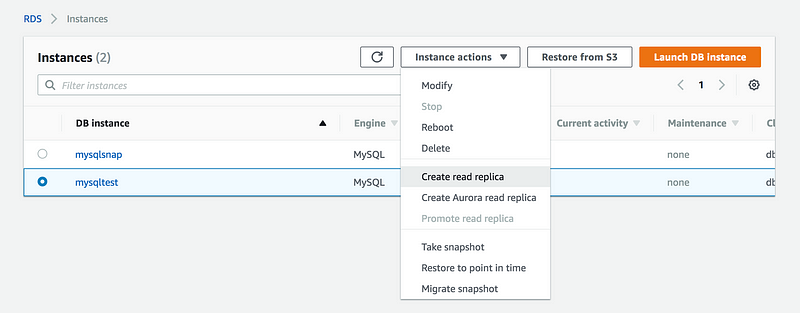
Now lets try to create Read Replica out of this database
Ohho no Create read replica option is not highlighted for me and the reason for that
We don’t have a snapshot
We don’t have an automated backups
Read replica is always created from a snapshot or the latest backup
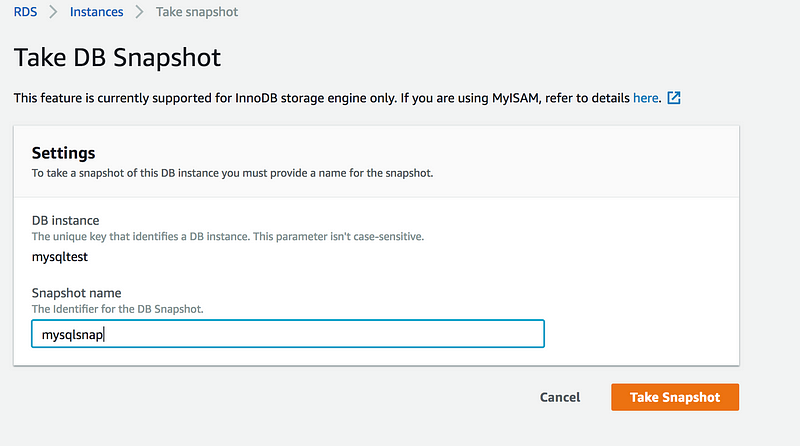
Let’s take a snapshot of this database
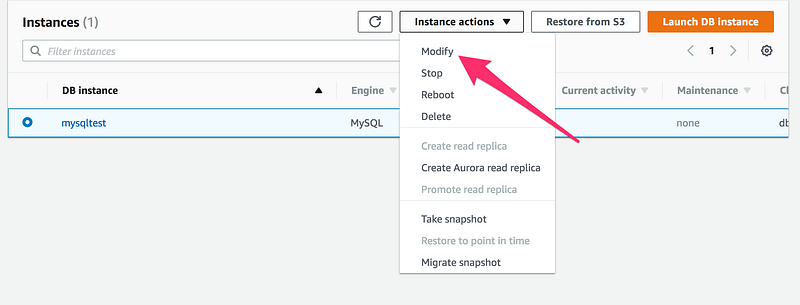
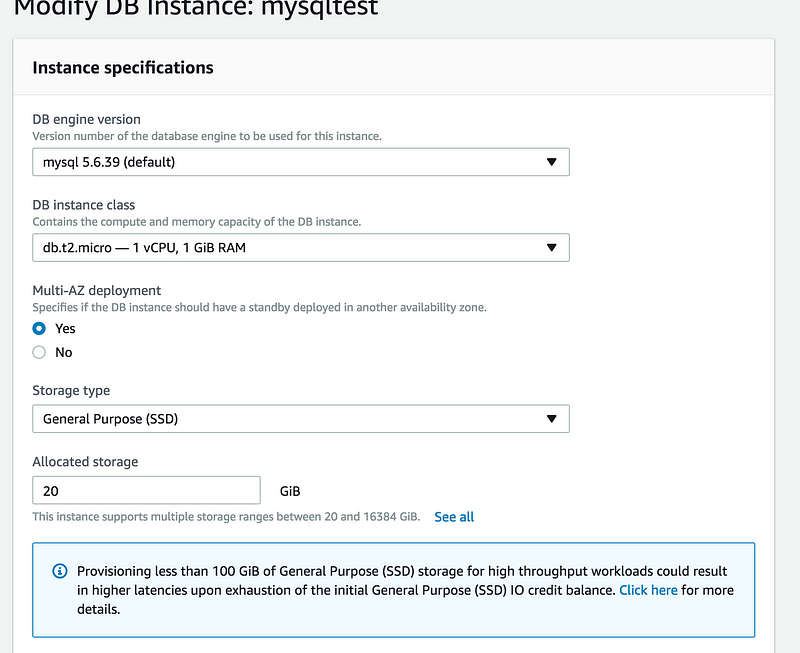
Once the snapshot creation is done, let’s try to convert this into multi-AZ. Go to Instance actions and click on Modify
These are the things you need to modify
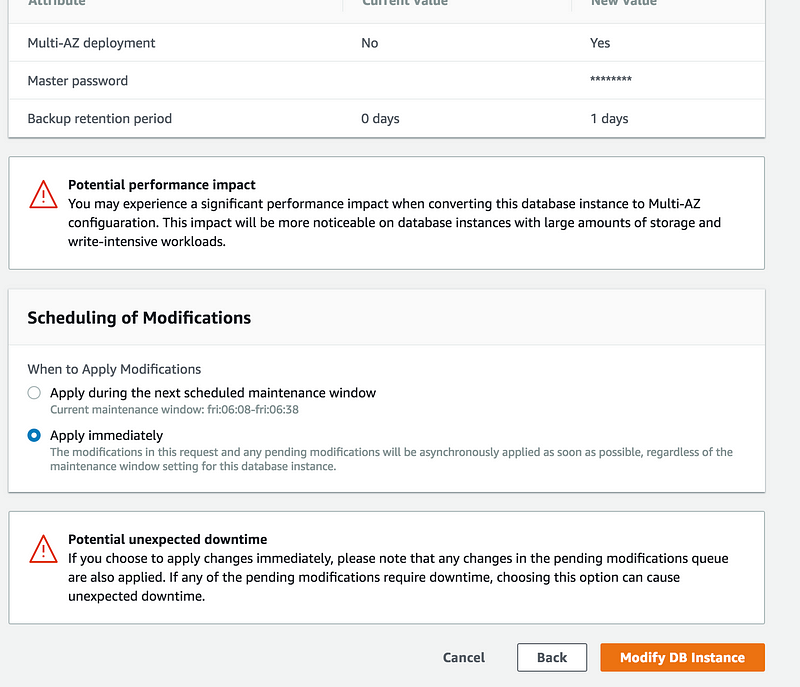
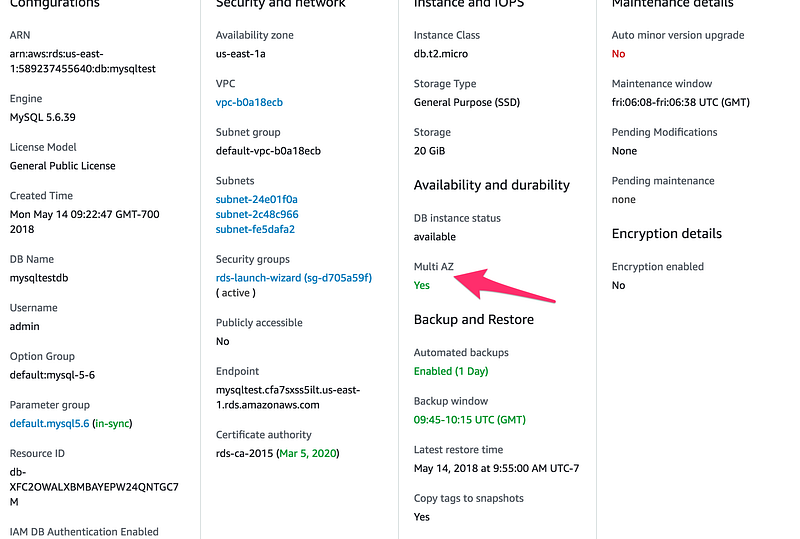
Multi-AZ set to Yes
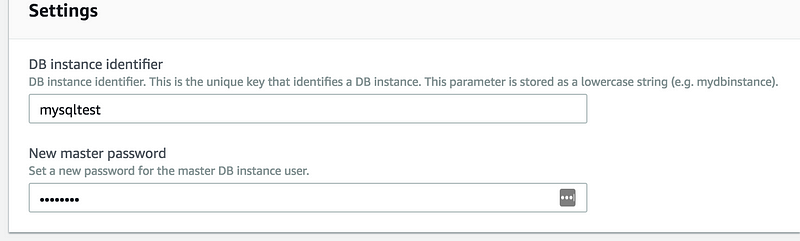
Under settings you need to enter the password again
I am enabling backup and set it to 1 day
On the final screen, you have the option
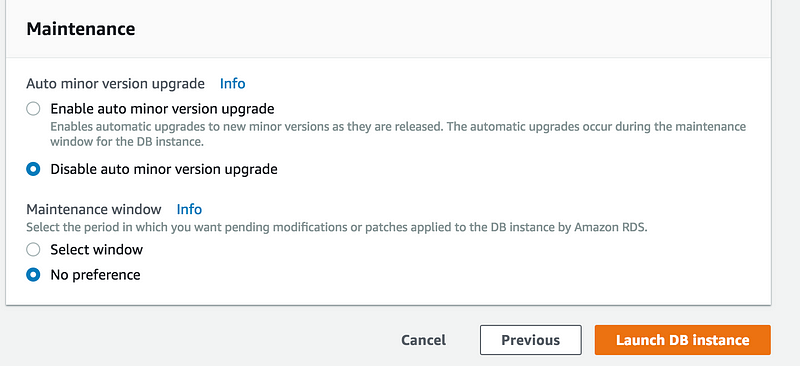
1: Apply during the next scheduled maintenance window
2: Apply immediately(This will cause a downtime)
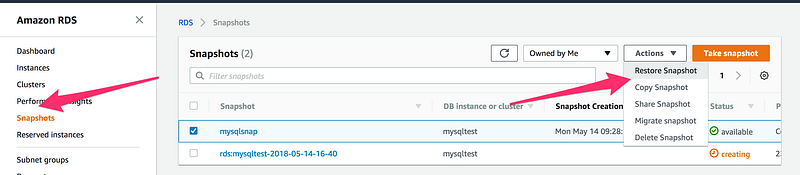
To restore a database from the snapshot
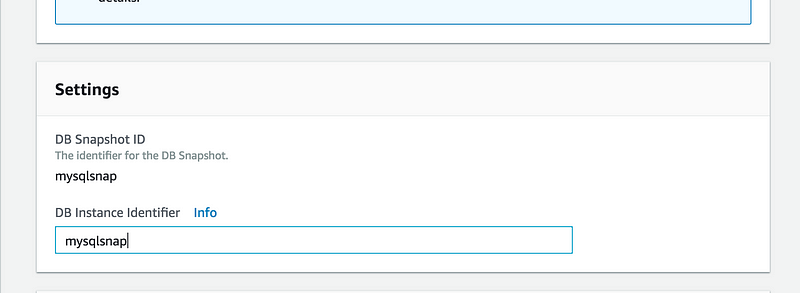
and then on the next screen, give DB Instance Identifier or any other setting you want to modify while restoring
To Verify if Multi-AZ is enabled, Click on the particular DB
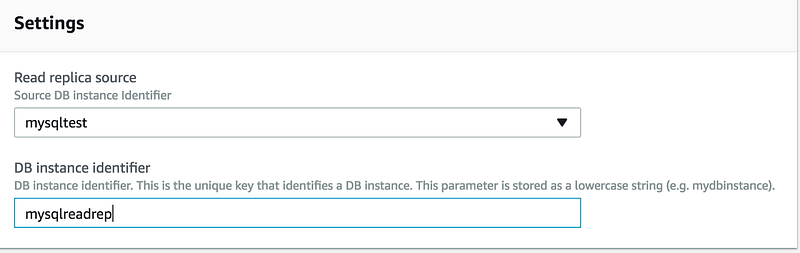
Now let’s try to create read-replica again, as you can see Create read replica tab is now enabled
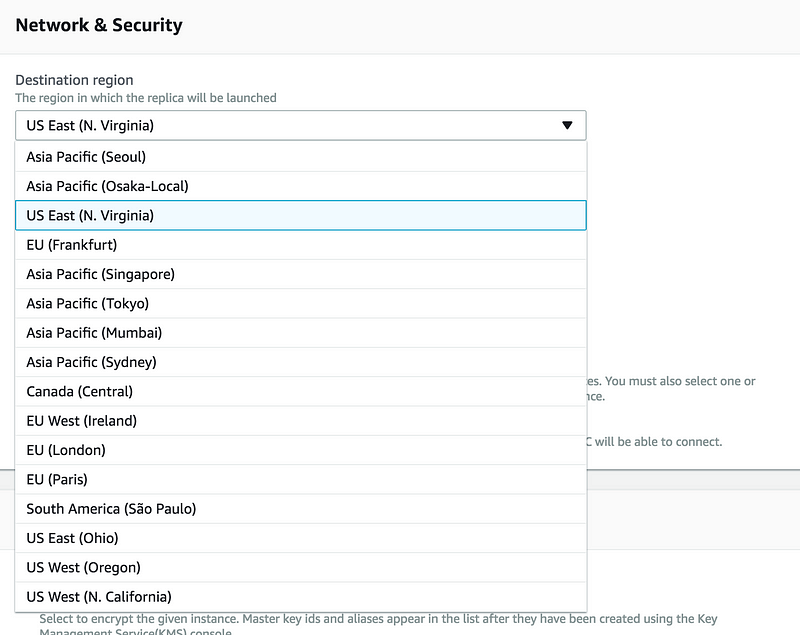
The Important thing to remember we can create read replica in any other region
Under the Settings tab, give it a unique name
Now whatever we have done manually here, let’s try to terraformed it
* allocated_storage: This is the amount in GB * storage_type: Type of storage we want to allocate(options avilable "standard" (magnetic), "gp2" (general purpose SSD), or "io1" (provisioned IOPS SSD) * engine: Database engine(for supported values check https://docs.aws.amazon.com/AmazonRDS/latest/APIReference/API_CreateDBInstance.html) eg: Oracle, Amazon Aurora,Postgres * engine_version: engine version to use * instance_class: instance type for rds instance * name: The name of the database to create when the DB instance is created. * username: Username for the master DB user. * password: Password for the master DB user * db_subnet_group_name: DB instance will be created in the VPC associated with the DB subnet group. If unspecified, will be created in the default VPC * vpc_security_group_ids: List of VPC security groups to associate. * allows_major_version_upgrade: Indicates that major version upgrades are allowed. Changing this parameter does not result in an outage and the change is asynchronously applied as soon as possible. * auto_minor_version_upgrade:Indicates that minor engine upgrades will be applied automatically to the DB instance during the maintenance window. Defaults to true. * backup_retention_period: The days to retain backups for. Must be between 0 and 35. When creating a Read Replica the value must be greater than 0 * backup_window:The daily time range (in UTC) during which automated backups are created if they are enabled. Must not overlap with maintenance_window * maintainence_window:The window to perform maintenance in. Syntax: "ddd:hh24:mi-ddd:hh24:mi". * multi_az: Specifies if the RDS instance is multi-AZ * skip_final_snapshot: Determines whether a final DB snapshot is created before the DB instance is deleted. If true is specified, no DBSnapshot is created. If false is specified, a DB snapshot is created before the DB instance is deleted, using the value from final_snapshot_identifier. Default is false
NOTE: Here we are storing mysql password in plan text, I will come up the blog shortly how to store this password in encrypted format.
We need to do some changes in order to make this work, by outputting the value of private subnet in terraform vpc module which will act an input to rds aws_db_subnet_group
output "private_subnet1" {
value = "${element(aws_subnet.private_subnet.*.id, 1 )}"
}
output "private_subnet2" {
value = "${element(aws_subnet.private_subnet.*.id, 2 )}"
}
Welcome to Day 7 of 21 Days of AWS using Terraform. Topic for today is Introduction to CloudWatch using terraform.
What is CloudWatch?
AWS CloudWatch is a monitoring service to monitor AWS resources, as well as the applications that run on AWS.
As per official documentation
Amazon CloudWatch monitors your Amazon Web Services (AWS) resources and the applications you run on AWS in real time. You can use CloudWatch to collect and track metrics, which are variables you can measure for your resources and applications.
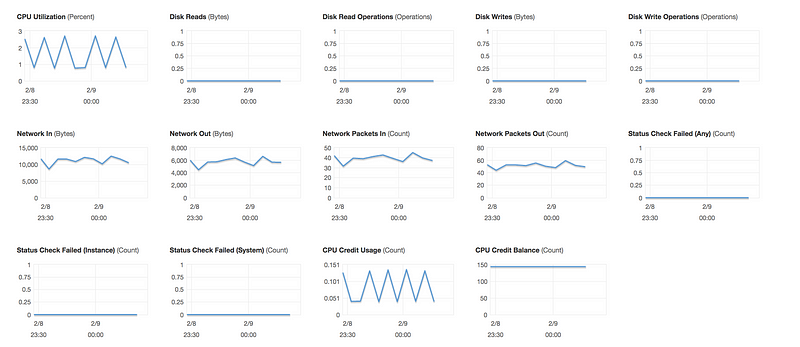
EC2/Host Level Metrics that CloudWatch monitors by default consist of
CPU
Network
Disk
Status Check
There are two types of status check
System status check: Monitor the AWS System on which your instance runs. It either requires AWS involvement to repair or you can fix it by yourself by just stop/start the instance(in case of EBS volumes).Examples of problems that can cause system status checks to fail
* Loss of network connectivity * Loss of system power * Software issues on the physical host * Hardware issues on the physical host that impact network reachability
Instance status check: Monitor the software and network configuration of an individual instance. It checks/detects problems that require your involvement to repair.
By default, EC2 monitoring is 5 minutes intervals but we can always enable detailed monitoring(1 minutes interval, but that will cost you some extra $$$)
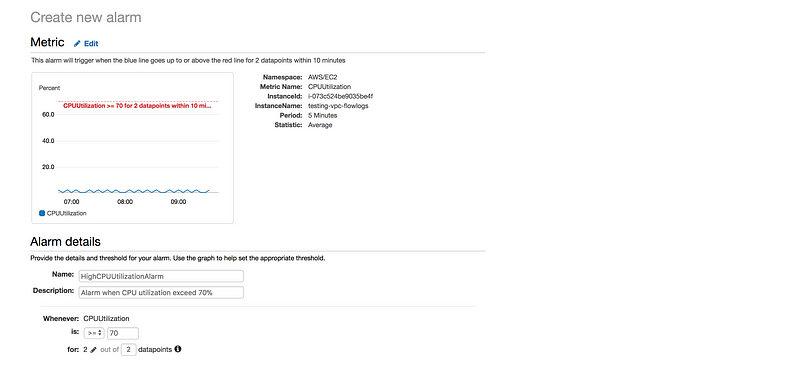
In the navigation pane, choose Alarms, Create Alarm.
Go to Metric → Select metric → EC2 → Per-Instance-Metrics → CPU Utilization → Select metric
Define the Alarm as follows
* Type the unique name for the alarm(eg: HighCPUUtilizationAlarm)
* Description of the alarm
* Under whenever,choose >= and type 70, for type 2. This specify that the alarm is triggered if the CPU usage is above 70% for two consecutive sampling period
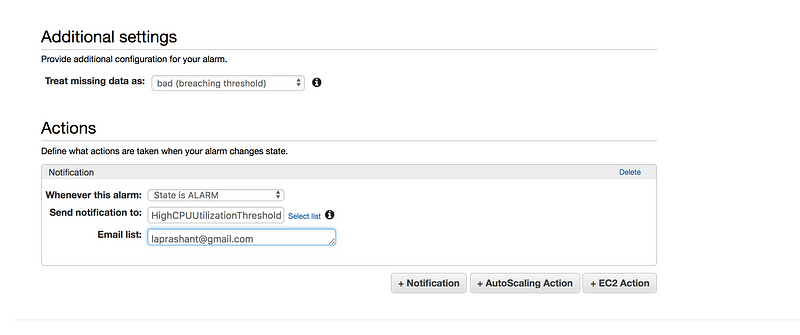
* Under Additional settings, for treat missing data as, choose bad(breaching threshold), as missing data points may indicate that the instance is down
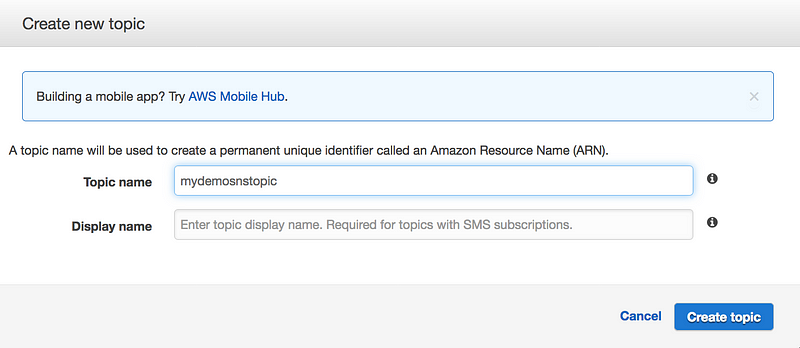
* Under Actions, for whenever this alarm, choose state is alarm. For Send notification to, select an exisiting SNS topic or create a new one
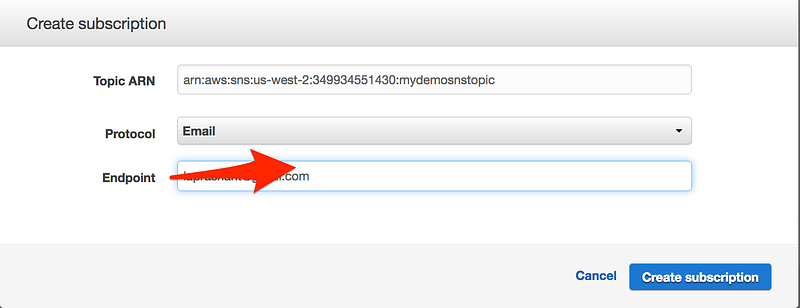
* To create a new SNS topic, choose new list, for send notification to, type a name of SNS topic(for eg: HighCPUUtilizationThreshold) and for Email list type a comma-seperated list of email addresses to be notified when the alarm changes to the ALARM state.
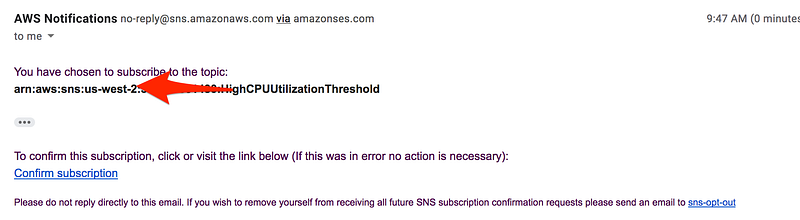
* Each email address is sent to a topic subscription confirmation email. You must confirm the subscription before notifications can be sent.
* Click on Create Alarm
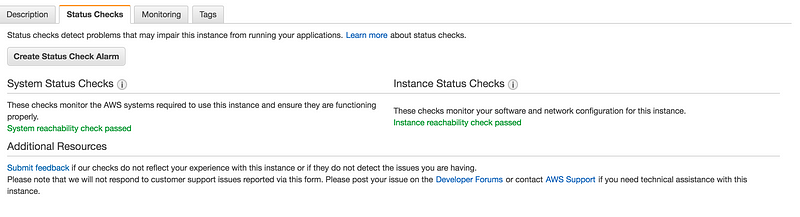
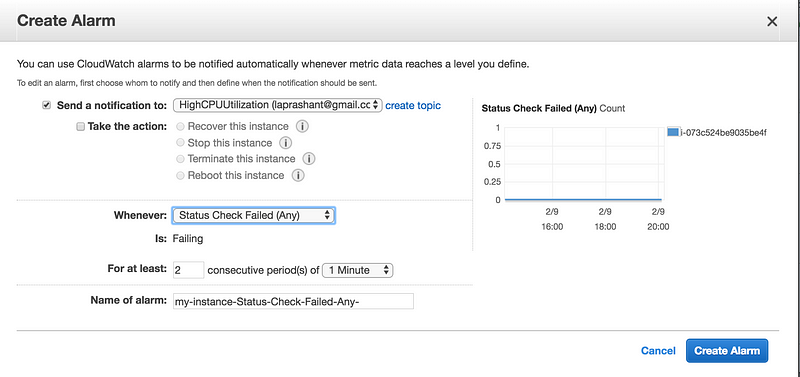
Scenario2: Create a status check alarm to notify when an instance has failed a status check
Creating a Status Check Alarm Using the AWS Console
Select the instance, choose the Status Checks tab, and choose to Create Status Check Alarm.
* You can create new SNS notification or use the exisiting one(I am using the existing one create in earlier example of high CPU utilization) * In Whenever, select the status check that you want to be notified about(options Status Check Failed(Any), Status Check Failed(Instance) and Status Check Failed(System) * In For at least, set the number of periods you want to evaluate and in consecutive periods, select the evaluation period duration before triggering the alarm and sending an email. * In Name of alarm, replace the default name with another name for the alarm. * Choose Create Alarm.
alarm_name – The descriptive name for the alarm. This name must be unique within the user’s AWS account
comparison_operator – The arithmetic operation to use when comparing the specified Statistic and Threshold. The specified Statistic value is used as the first operand. Either of the following is supported: GreaterThanOrEqualToThreshold, GreaterThanThreshold, LessThanThreshold, LessThanOrEqualToThreshold.
evaluation_periods – The number of periods over which data is compared to the specified threshold.
metric_name – The name for the alarm’s associated metric.
namespace – The namespace for the alarm’s associated metric.
period – The period in seconds over which the specified statistic is applied.
statistic – The statistic to apply to the alarm’s associated metric. Either of the following is supported: SampleCount, Average, Sum, Minimum, Maximum
threshold – The value against which the specified statistic is compared.
alarm_actions – The list of actions to execute when this alarm transitions into an ALARM state from any other state. Each action is specified as an Amazon Resource Name (ARN).
dimensions – The dimensions for the alarm’s associated metric.
We need to modify our SNS module a little bit where the output of SNS arn will act as a input to this cloudwatch module.
output "sns_arn" {
value = "${aws_sns_topic.my-test-alarm.arn}"
}
Same way output of EC2 module will act as an input to cloudwatch module
output "instance_id" {
value = "${element(aws_instance.my-test-instance.*.id, 1)}"
}
There is a bug in terraform code, where I can’t specify multiple instances
output "instance_id" {
value = "${aws_instance.my-test-instance.*.id)}"
}
If we try to use the above it’s will fail due to below error
Error: Incorrect attribute value type
on cloudwatch/main.tf line 12, in resource "aws_cloudwatch_metric_alarm" "cpu-utilization":
12: dimensions = {
Inappropriate value for attribute "dimensions": element "InstanceId": string
required.
Error: Incorrect attribute value type
on cloudwatch/main.tf line 29, in resource "aws_cloudwatch_metric_alarm" "instance-health-check":
29: dimensions = {
Inappropriate value for attribute "dimensions": element "InstanceId": string
required.
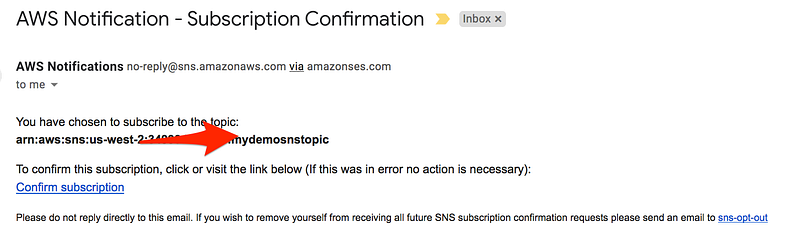
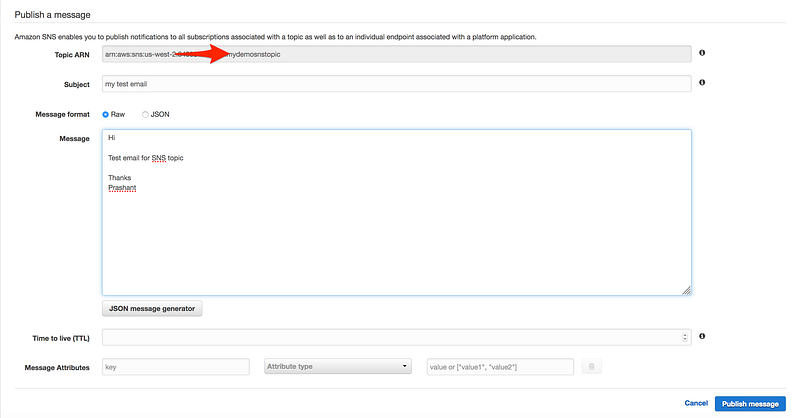
Welcome to Day 6 of 21 Days of AWS using Terraform. Topic for today is Introduction to Simple Notification to Service(SNS) using terraform.
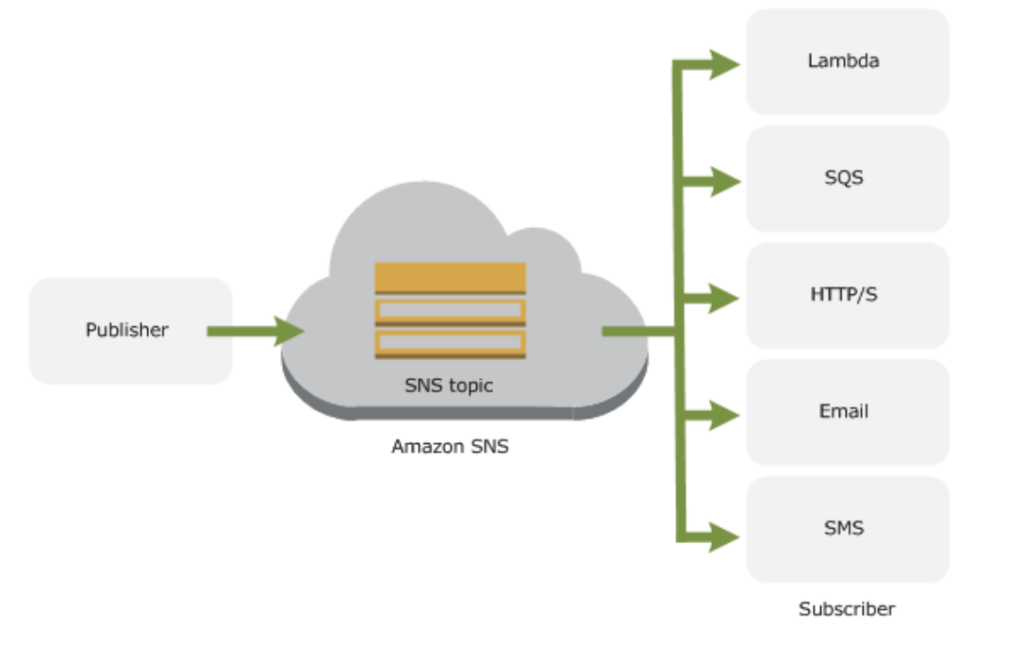
What is SNS?
As per official documentation
AWS SNS is a web service that coordinates and manages the delivery or sending of messages to subscribing endpoints or clients.
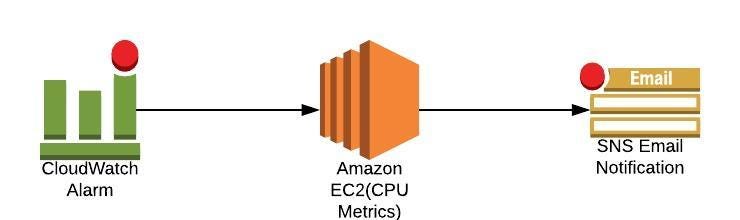
In case of cloudwatch(high CPU utilization or System/Instance Status Check) when the certain event occurs and SNS is used to send a notification. CloudWatch in combination with SNS creates a full monitoring solution with notifies the administrator in case of any environment issue(high CPU, Downtime…).
The entity that triggers the sending of a message(eg: CloudWatch Alarm, Any application or S3 events)
Topic
Object to which you publish your message(≤256KB)
Subscriber subscribe to the topic to receive the message
Soft limit of 10 million subscribers
Subscriber
An endpoint to a message is sent. Message are simultaneously pushed to the subscriber
As you can see it follows the publish-subscribe(pub-sub) messaging paradigm with notification being delivered to the client using a push mechanism that eliminates the need to periodically check or poll for new information and updates.
To prevent the message from being lost, all messages published to Amazon SNS are stored redundantly across multiple Availability Zones.
The local-exec provisioner invokes a local executable after a resource is created. This invokes a process on the machine running Terraform, not on the resource. For more info https://www.terraform.io/docs/provisioners/local-exec.html
variables.tf
variable "alarms_email" {}
outputs.tf
output "sns_arn" {
value = "${aws_sns_topic.my-test-alarm.arn}"
}
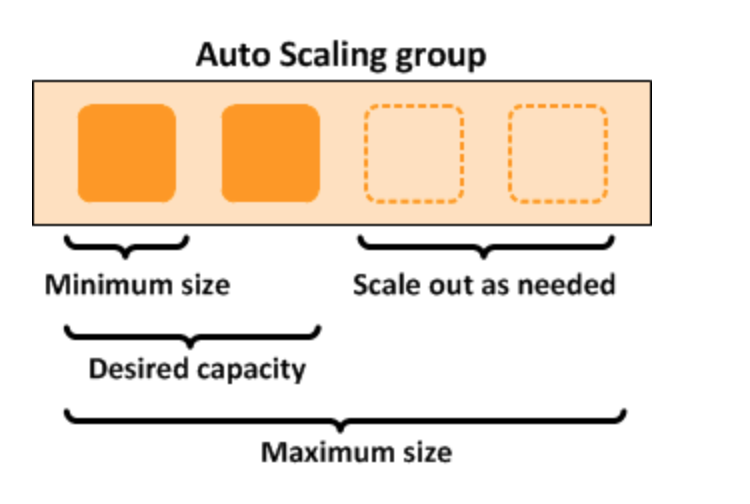
Welcome to Day 5 of 21 Days of AWS using Terraform, So far we build VPC ,EC2 and Application Load Balancer, let’s build Auto Scaling Group and rather then creating an instance via EC2 module, let auto-scaling group take care of it based on load.
What is Auto Scaling?
What auto-scaling will do, it ensures that we have a correct number of EC2 instances to handle the load of your applications.
How Auto Scaling works
It all started with the creation of the Auto Scaling group which is the collection of EC2 instances.
You can specify a minimum number of instances and AWS EC2 Auto Scaling ensures that your group never goes below this size.
The same way we can specify the maximum number of instances and AWS EC2 Auto Scaling ensures that your group never goes above this size.
If we specify the desired capacity, AWS EC2 Auto Scaling ensures that your group has this many instances.
Configuration templates(launch template or launch configuration): Specify Information such as AMI ID, instance type, key pair, security group
If we specify scaling policies then AWS EC2 Auto Scaling can launch or terminate instances as demand on your application increased or decreased. For eg: We can configure a group to scale based on the occurrence of specified conditions(dynamic scaling) or on a schedule.
Scaling policies we define adjust the minimum or a maximum number of instances based on the criteria we specify.
Step1: The first step in creating the AutoScaling Group is to create a launch configuration, which specifies how to configure each EC2 instance in the autoscaling group.
One of the available lifecycle settings are create_before_destroy, which, if set to true, tells Terraform to always create a replacement resource before destroying the original resource. For example, if you set create_before_destroy to true on an EC2 Instance, then whenever you make a change to that Instance, Terraform will first create a new EC2 Instance, wait for it to come up, and then remove the old EC2 Instance.
The catch with the create_before_destroy the parameter is that if you set it to true on resource X, you also have to set it to true on every resource that X depends on (if you forget, you’ll get errors about cyclical dependencies).
We need to make slight changes to our VPC module outputs.tf file, as the output of subnet block, will not act as an input to autoscaling group vpc_zone_identifier
output "public_subnets" {
value = "${aws_subnet.public_subnet.*.id}"
}
Same way we need to output the target arn from alb module so that it can act as an input to auto-scaling group module(target_group_arn)
output "alb_target_group_arn" {
value = "${aws_lb_target_group.my-target-group.arn}"
}
Final word, as we are now using auto-scale/auto-launch configuration to spin up our instance we probably don’t need EC2 module. I am leaving it for the time being but for ALB let me comment out the code
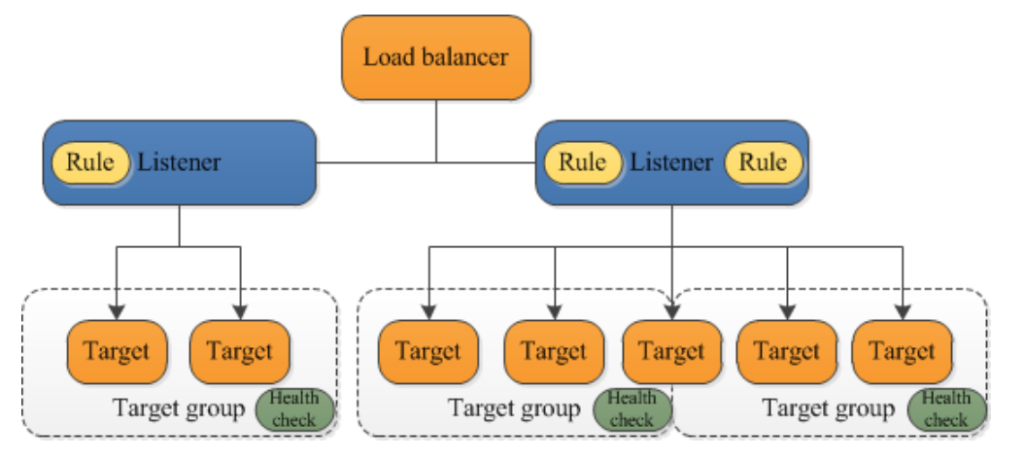
Welcome to Day 4 of 21 Days of AWS using Terraform, So far we build VPC and EC2, let’s build Application Load Balancer and add two instances behind it. This is going to be a modular approach i.e we are going to get vpc id,subnet1 and subnet2 created during the VPC module and instance id from EC2 module.
The Application Load Balancer is a feature of ElasticLoad Balancing that allows a developer to configure and route incoming end-user traffic to applications based in the Amazon Web Services (AWS) public cloud.
Features
Layer7 load balancer(HTTP and HTTPs traffic)
Support Path and Host-based routing(which let you route traffic to different target group)
Listener support IPv6
Some Key Terms
Target Group
Target types:
Instance types: Route traffic to the Primary Private IP address of that Instance
IP: Route traffic to a specified IP address
Lambda function
Health Check
Determines whether to send traffic to a given instance
Each instance must pass its a health check
Sends HTTP GET request and looks for a specific response/success code
health_check: Your Application Load Balancer periodically sends requests to its registered targets to test their status. These tests are called health checks
interval: The approximate amount of time, in seconds, between health checks of an individual target. Minimum value 5 seconds, Maximum value 300 seconds. Default 30 seconds.
path: The destination for the health check request
protocol: The protocol to use to connect with the target. Defaults to HTTP
timeout:The amount of time, in seconds, during which no response means a failed health check. For Application Load Balancers, the range is 2 to 60 seconds and the default is 5 seconds
healthy_threshold: The number of consecutive health checks successes required before considering an unhealthy target healthy. Defaults to 3.
unhealthy_threshold: The number of consecutive health check failures required before considering the target unhealthy
matcher: The HTTP codes to use when checking for a successful response from a target. You can specify multiple values (for example, "200,202") or a range of values (for example, "200-299")name: The name of the target group. If omitted, Terraform will assign a random, unique name.
port: The port on which targets receive traffic
protocol: The protocol to use for routing traffic to the targets. Should be one of "TCP", "TLS", "HTTP" or "HTTPS". Required when target_type is instance or ip
vpc_id:The identifier of the VPC in which to create the target group. This value we will get from the VPC module we built earlier
target_type: The type of target that you must specify when registering targets with this target group.Possible values instance id, ip address
The VPC module we built earlier, we need to modify it a little built by outputting the value of VPC id(outputs.tf) which will act as an input to Application Load Balancer Module
output "vpc_id" {
value = "${aws_vpc.main.id}"
}
Step2: Provides the ability to register instances with an Application Load Balancer (ALB)
target_group_arn: The ARN of the target group with which to register targets target_id: The ID of the target. This is the Instance ID for an instance. We will get this value from EC2 module port: The port on which targets receive traffic.
We need to modify the EC2 module(outputs.tf) by outputting the value of EC2 id which will act as an input to Application Load Balancer Module
output "instance1_id" {
value = "${element(aws_instance.my-test-instance.*.id, 1)}"
}
output "instance2_id" {
value = "${element(aws_instance.my-test-instance.*.id, 2)}"
}
element(list, index) – Returns a single element from a list at the given index. If the index is greater than the number of elements, this function will wrap using a standard mod algorithm. This function only works on flat lists.
name: The name of the LB. This name must be unique within your AWS account, can have a maximum of 32 characters, must contain only alphanumeric characters or hyphens, and must not begin or end with a hyphen. If not specified, Terraform will autogenerate a name beginning with tf-lb (This part is important as Terraform auto internal: If true, the LB will be internal. load_balancer_type: The type of load balancer to create. Possible values are application or network. The default value is the application. ip_address_type: The type of IP addresses used by the subnets for your load balancer. The possible values are ipv4 and dualstack subnets: A list of subnet IDs to attach to the LB. In this case, I am attaching two public subnets we created during load balancer creation. This value we will get out from the VPC module. tags: A mapping of tags to assign to the resource.
We need to modify the VPC module and output the value of two subnet id which will act as an input to application load balancer module
output "subnet1" {
value = "${element(aws_subnet.public_subnet.*.id, 1 )}"
}
output "subnet2" {
value = "${element(aws_subnet.public_subnet.*.id, 2 )}"
}
load_balancer_arn – The ARN of the load balancer(we created in step3)
port – (Required) The port on which the load balancer is listening.
protocol – (Optional) The protocol for connections from clients to the load balancer. Valid values are TCP, TLS, UDP, TCP_UDP, HTTP and HTTPS. Defaults to HTTP.